目录
- 1. 云硬盘
- 2. 对象存储
- 3. 表单上传案例
- 4. 服务上传验证
- 5. 云数据库
- 6. 云数据库操作
- 7. 服务连接云数据库
- 8. 新一代原生数据库
- 9 阿里云PolarDB生产最佳实践
1. 云硬盘
- HDD(普通云盘)
特征: 性能一般, IOPS大概在数百左右。
应用场景: 数据不被经常访问或者低I/O负载的应用场景,需要低成本并且有随机读写I/O的应用环境。
- 混合HDD(高效云盘)
特征: 结合HDD和SSD硬盘构建, IOPS为1000~5000左右。
应用场景: 开发与测试业务、系统盘。
- SSD云盘
特征: 具有稳定的IO能力, IOPS能够达到10000~25000左右。
应用场景:I/O密集型应用、中小型关系数据库、NoSQL数据库。
- 企业级SSD(ESSD云盘)
特征: 优化增强的SSD云盘, 一般是采用企业级的闪存硬件, IOPS能够达到10000~1000000左右。
应用场景: 大型OLTP数据库等关系型数据库、NoSQL数据库、ELK分布式日志存储等。
测试:
- 安装fio工具
yum -y install fio
- iops测试
fio --name=disktest --filename=~/disktest --rw=randread --refill_buffers --bs=4k --size=1G -runtime=5 -direct=1 -iodepth=128 -ioengine=libaio
输出结果:
[root@iZm5egp1t778ocdk7f1j6fZ ~]# fio --name=disktest --filename=~/disktest --rw=randread --refill_buffers --bs=4k --size=1G -runtime=5 -direct=1 -iodepth=128 -ioengine=libaio
disktest: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=128
fio-3.7
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=8560KiB/s,w=0KiB/s][r=2140,w=0 IOPS][eta 00m:00s]
disktest: (groupid=0, jobs=1): err= 0: pid=1417: Thu Nov 12 22:09:25 2020
read: IOPS=2151, BW=8606KiB/s (8812kB/s)(42.3MiB/5032msec)
slat (usec): min=2, max=166, avg= 6.54, stdev= 3.69
clat (usec): min=794, max=157946, avg=59467.61, stdev=47971.33
lat (usec): min=799, max=157950, avg=59474.73, stdev=47971.03
clat percentiles (usec):
| 1.00th=[ 1172], 5.00th=[ 1434], 10.00th=[ 1614], 20.00th=[ 1860],
| 30.00th=[ 2147], 40.00th=[ 2999], 50.00th=[ 98042], 60.00th=[ 98042],
| 70.00th=[ 99091], 80.00th=[ 99091], 90.00th=[ 99091], 95.00th=[100140],
| 99.00th=[127402], 99.50th=[127402], 99.90th=[156238], 99.95th=[156238],
| 99.99th=[158335]
bw ( KiB/s): min= 8544, max= 8560, per=99.46%, avg=8558.40, stdev= 5.06, samples=10
iops : min= 2136, max= 2140, avg=2139.60, stdev= 1.26, samples=10
lat (usec): 1000=0.16%
lat (msec): 2=25.15%, 4=15.13%, 10=0.03%, 50=0.59%, 100=56.23%
lat (msec): 250=2.71%
cpu : usr=0.58%, sys=1.93%, ctx=1154, majf=0, minf=163
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.3%, >=64=99.4%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1%
issued rwts: total=10826,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency: target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs):
READ: bw=8606KiB/s (8812kB/s), 8606KiB/s-8606KiB/s (8812kB/s-8812kB/s), io=42.3MiB (44.3MB), run=5032-5032msec
Disk stats (read/write):
vda: ios=10486/0, merge=0/1, ticks=614779/0, in_queue=485314, util=75.89%
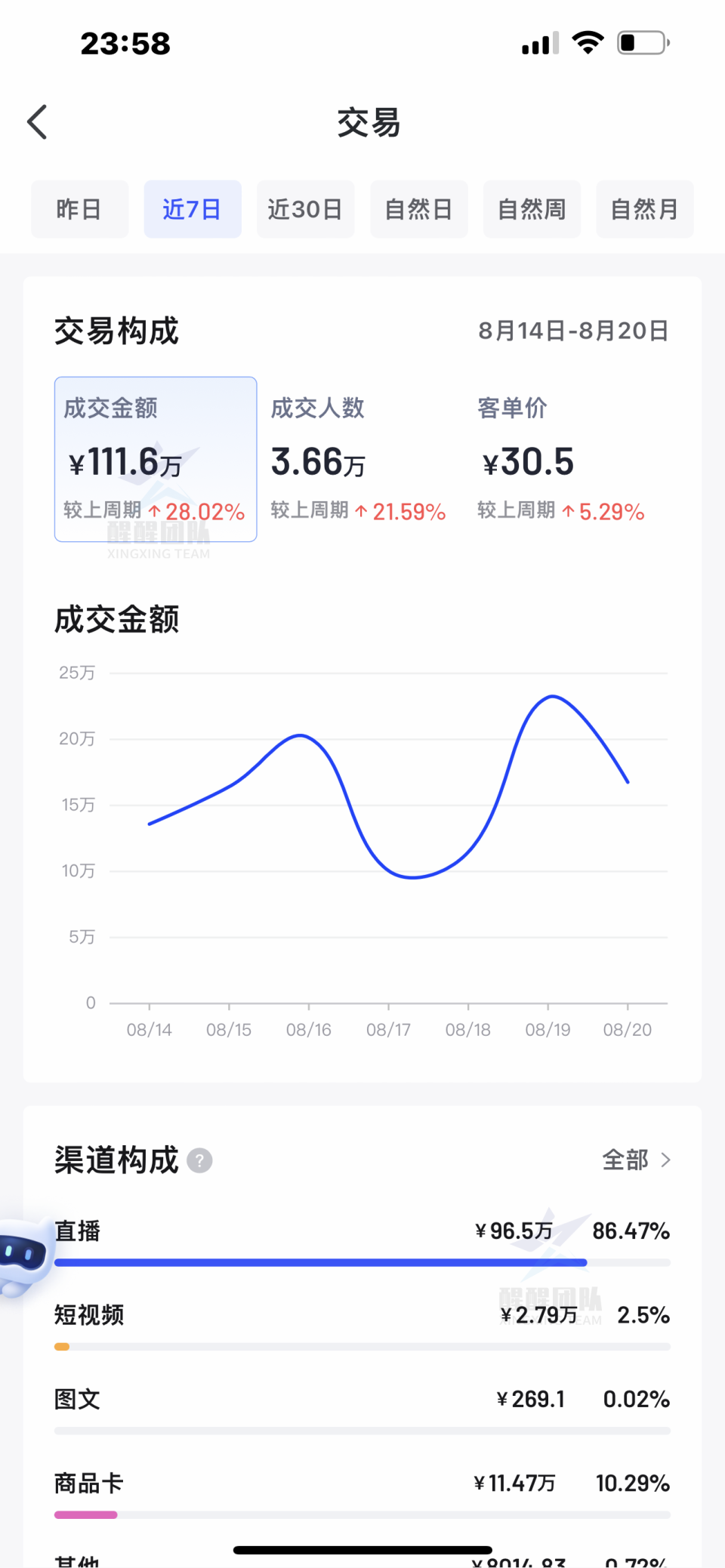
iops平均达到2139.60,与高效云盘标示的2120基本是一致。
也可以挂在动态硬盘进行测试, 不同的类型和存储空间, IOPS是不一样:
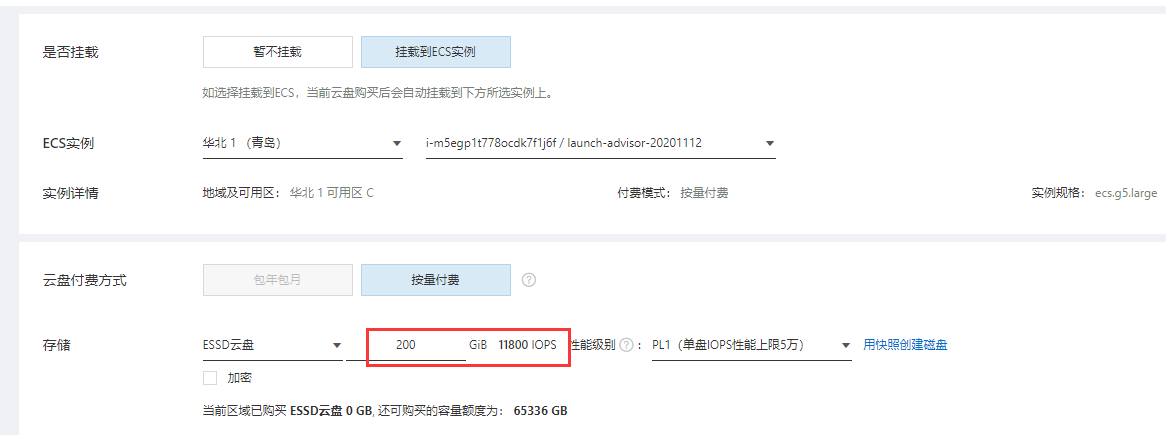
2. 对象存储
- Amazon S3 vs 阿里云 OSS
Amazon S3,全称亚马逊简易存储服务(Amazon Simple Storage Service)
阿里云 OSS(Object Storage Service,简称OSS),是阿里云对外提供的海量、安全、低成本、高可靠的云存储服务。
对比:
- 对象存储VS云硬盘
-
提供接口访问
对象存储本质是一个网络化的服务, 云硬盘是挂载到虚拟机的虚拟硬盘,必须连接到虚拟机才能操作。
-
存储结构不一致
云硬盘是一个可以作为一个真正的文件系统, 而云存储是一个近似键值(key和value)的存储服务。
-
海量数据存储
云硬盘一般会受自身容量的限制, 不能支撑海量数据存储, 对象存储得益于其底层设计, 天生就能够支撑大数据存储。对象存储服务不仅可以支持海量的小文件, 也适合处理大型文件。
- 实践操作
流程:

-
开通OSS服务OSS产品详情页
-
创建存储空间, Bucket名称要具备唯一性。
-
开通对应的访问权限
不要采用主账号,会存在安全隐患, 授权给RAM用户。

- 添加依赖
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>3.10.2</version>
</dependency>
- 上传文件
UploadApplication:
public class UploadApplication {
public static void main(String[] args) throws Exception{
// 创建OSSClient实例。
OSS ossClient = new OSSClientBuilder().build(Constants.endpoint, Constants.accessKeyId, Constants.accessKeySecret);
// 创建PutObjectRequest对象。
PutObjectRequest putObjectRequest = new PutObjectRequest(Constants.bucketName, "readme", new File("d:/readme.txt"));
// 上传文件。
PutObjectResult result = ossClient.putObject(putObjectRequest);
System.out.println("upload complete.");
// 关闭OSSClient。
ossClient.shutdown();
}
}
- 下载文件
DownloadApplication:
public class DownloadApplication {
public static void main(String[] args) {
// Endpoint以杭州为例,其它Region请按实际情况填写。
String endpoint = Constants.endpoint;
// 阿里云主账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM账号进行API访问或日常运维,请登录 https://ram.console.aliyun.com 创建RAM账号。
String accessKeyId = Constants.accessKeyId;
String accessKeySecret = Constants.accessKeySecret;
String bucketName = Constants.bucketName;
String objectName = "readme";
// 创建OSSClient实例。
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
// 下载OSS文件到本地文件。如果指定的本地文件存在会覆盖,不存在则新建。
ossClient.getObject(new GetObjectRequest(bucketName, objectName), new File("e:/"+ objectName));
// 关闭OSSClient。
ossClient.shutdown();
System.out.println("download complete.");
}
}
3. 表单上传案例
- 应用场景
表单上传非常适合嵌入在HTML网页中来上传Object,比较常见的场景是网站应用,以招聘网站为例, 流程比对:
- 不使用表单上传
- 网站用户上传简历。
- 网站服务器回应上传页面。
- 简历被上传到网站服务器。
- 网站服务器再将简历上传到OSS。
- 采用表单上传
- 网站用户上传简历。
- 网站服务器回应上传页面。
- 简历上传到OSS。
使用表单上传,少了一步转发流程, 并且在上传量过大时, 减少了业务应用方服务扩容的压力。
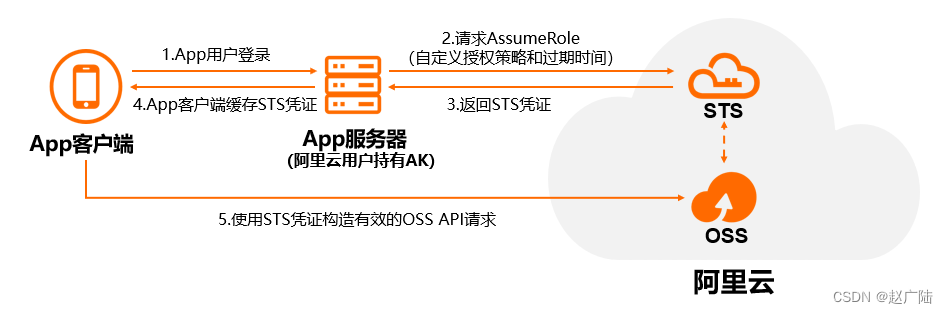
- 通过STS临时授权访问OSS
通过阿里云STS(Security Token Service)进行临时授权访问, 可以为第三方应用颁发一个自定义时效和权限的访问凭证, 用以保障服务安全性(类似于OAuth2的授权码访问模式)。
实现机制:
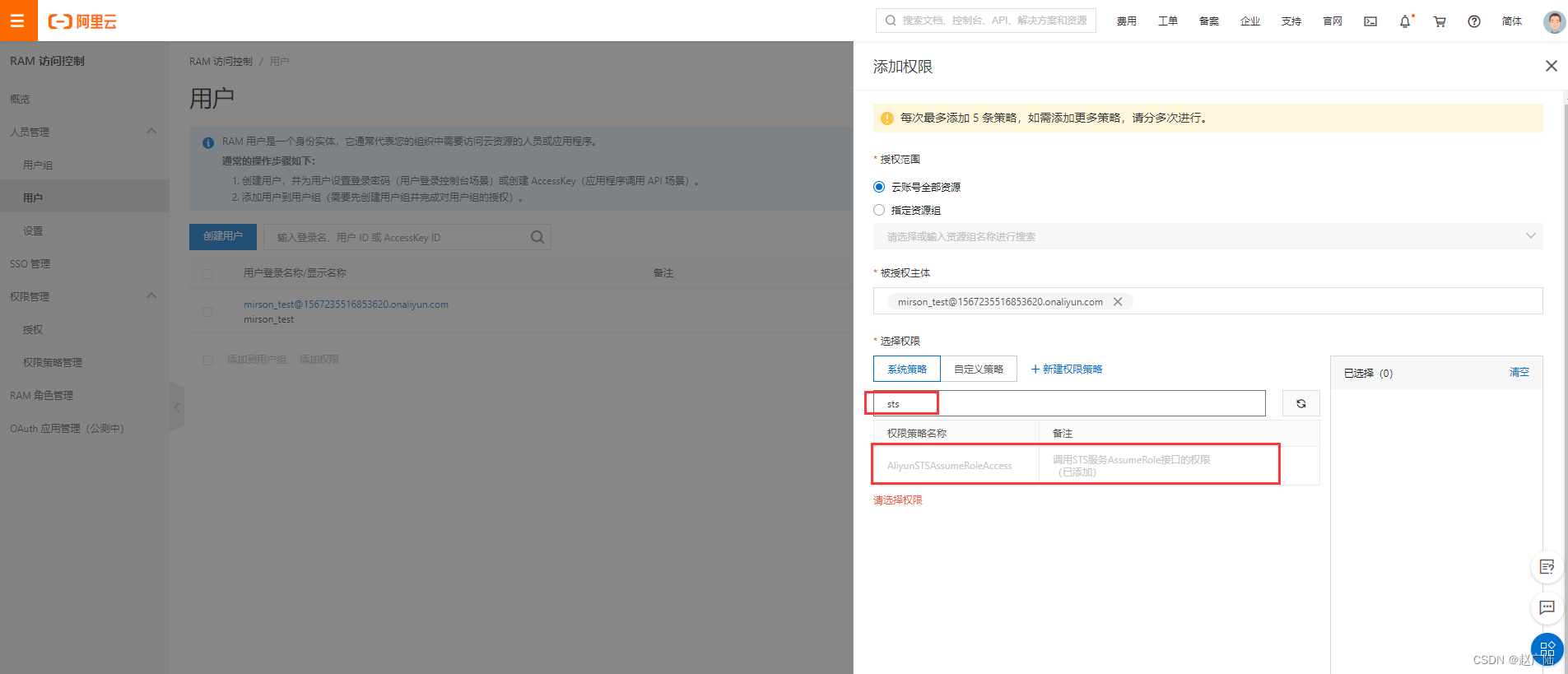
- RAM用户STS授权配置
进入RAM访问控制后台->用户->添加权限, 输入框填写"sts"过滤, 选择AliyunSTSAssumeRoleAccess权限。
- 创建权限策略
输入权限策略名称, 可以选择脚本配置, 更为灵活。
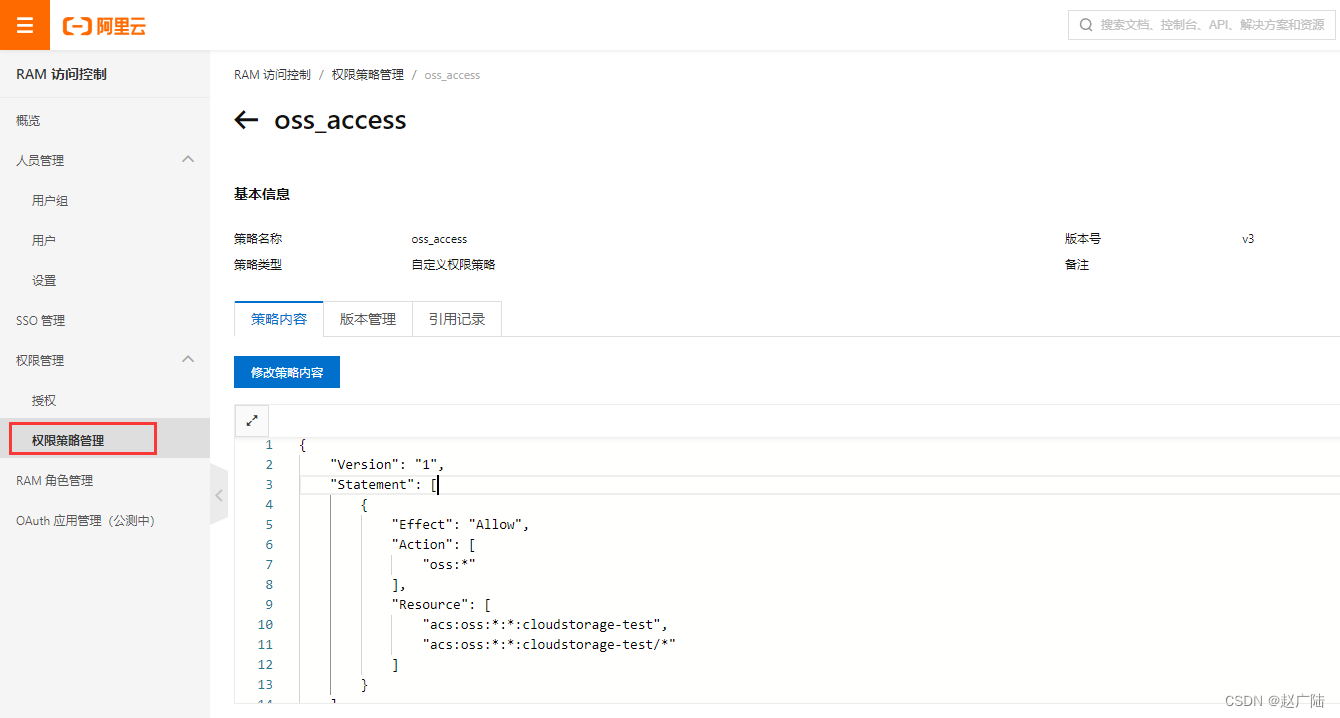
策略内容:
{
"Version": "1",
"Statement": [
{
"Effect": "Allow",
"Action": [
"oss:*"
],
"Resource": [
"acs:oss:*:*:cloudstorage-test",
"acs:oss:*:*:cloudstorage-test/*"
]
}
]
}
意思是对名称为cloudstorage-test的Bucket具有完全控制权限。如果更细力度的控制, 可以修改Action,例如:
"Action": [ "oss:ListBuckets", "oss:GetBucketStat", "oss:GetBucketInfo", "oss:GetBucketTagging", "oss:GetBucketAcl" ],
- 创建访问角色
打开"RAM角色管理",点击"创建RAM角色“,可信实体类型选择“阿里云账号”
接下来输入角色名称, 选择当前云账号;添加上面所创建的权限策略“oss_access”。
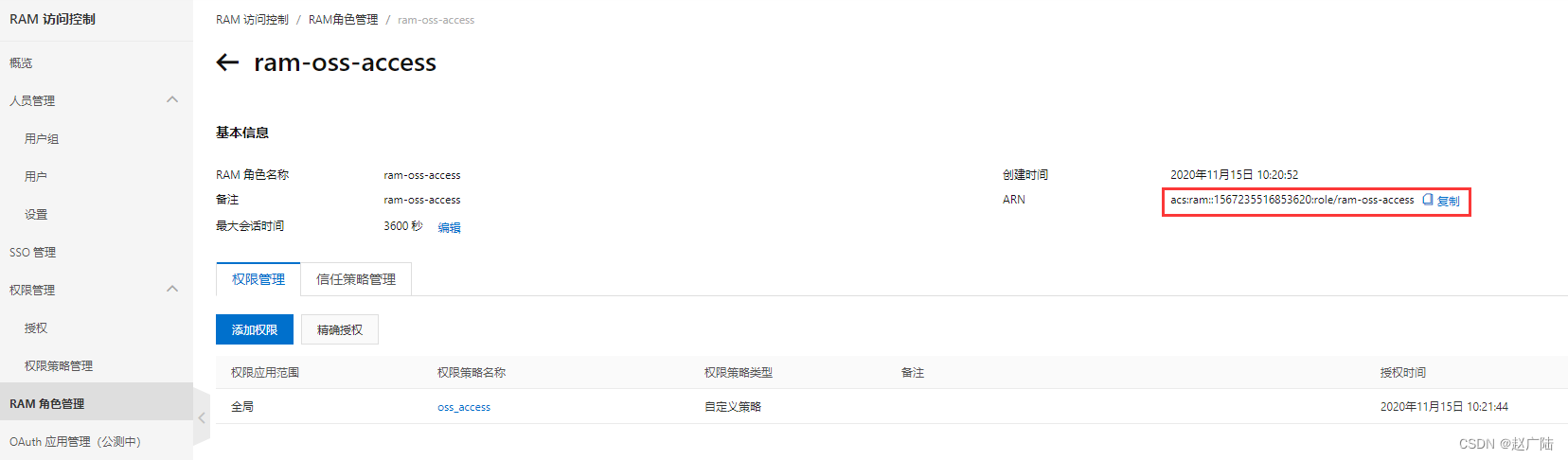
配置完成后, 会生成一个ARN值, 需要将它记录下来。
- 申请STS的访问TOKEN信息
StsServiceApplication代码:
public class StsServiceApplication {
public static void main(String[] args) {
String endpoint = "sts.cn-beijing.aliyuncs.com";
String AccessKeyId = Constants.accessKeyId;
String accessKeySecret = Constants.accessKeySecret;
String roleArn = "acs:ram::1567235516853620:role/ram-oss-access";
String roleSessionName = "oss_access_session";
String policy = "{\n" +
" \"Version\": \"1\", \n" +
" \"Statement\": [\n" +
" {\n" +
"\"Action\": [\n" +
" \"oss:*\"\n" +
"], \n" +
"\"Resource\": [\n" +
" \"acs:oss:*:*:*\" \n" +
"], \n" +
"\"Effect\": \"Allow\"\n" +
" }\n" +
" ]\n" +
"}";
try {
// 添加endpoint(直接使用STS endpoint,前两个参数留空,无需添加region ID)
DefaultProfile.addEndpoint("", "", "Sts", endpoint);
// 构造default profile(参数留空,无需添加region ID)
IClientProfile profile = DefaultProfile.getProfile("", AccessKeyId, accessKeySecret);
// 用profile构造client
DefaultAcsClient client = new DefaultAcsClient(profile);
final AssumeRoleRequest request = new AssumeRoleRequest();
request.setMethod(MethodType.POST);
request.setRoleArn(roleArn);
request.setRoleSessionName(roleSessionName);
request.setPolicy(policy); // 若policy为空,则用户将获得该角色下所有权限
request.setDurationSeconds(1000L); // 设置凭证有效时间
final AssumeRoleResponse response = client.getAcsResponse(request);
System.out.println("Expiration: " + response.getCredentials().getExpiration());
System.out.println("Access Key Id: " + response.getCredentials().getAccessKeyId());
System.out.println("Access Key Secret: " + response.getCredentials().getAccessKeySecret());
System.out.println("Security Token: " + response.getCredentials().getSecurityToken());
System.out.println("RequestId: " + response.getRequestId());
} catch (ClientException e) {
System.out.println("Failed:");
System.out.println("Error code: " + e.getErrCode());
System.out.println("Error message: " + e.getErrMsg());
System.out.println("RequestId: " + e.getRequestId());
}
}
}
返回结果:
Expiration: 2020-11-15T06:37:51Z
Access Key Id: STS.NT2Mshx5eaKbLScAzcwXLLK5V
Access Key Secret: 7buxRohgRr6vT1EVAqq4FWjxaUFRQMuC4vvV55utenkJ
Security Token: CAISjwJ1q6Ft5B2yfSjIr5eHBsnclepE1omJTnXSpXo2e9dgo46etDz2IHxMenFgA+sfv/0ynGBR5/YSlrt0UIRyTEfPYNBr2Y9a6higZIyZdz4iUQhC2vOfAmG2J0PR7q27OpfELr70fvOqdCqz9Etayqf7cjOPRkGsNYbz57dsctUQWHvXD1dBH8wEZHEhyqkgOGDWKOymPzPzn2PUFzAIgAdnjn5l4qnNpa/54xHF3lrh0b1X9cajYLrcNpQyY80kDorsgrwrLfSbiBQ9sUYaqP1E64Vf4irCs92nBF1c3g6LKeK88Kc0cFcnPvhgQPcV9aWkxaQp6rzJ8Z7+zlNKJvoQWi/USZu70Fd2+ykG8lpTGoABiIGFt+WCBkX/yLkY3uHDiWq4Uud32DzXWQAQpGmOWXwYzPRepi0XCcC029hPoXwCsj6mWbd/Ls2bUQsLUPtG3ozr6WawG2XUBXgZI5dNip8dZJCWZSet9qGsNXubhA3hTC+Wi7MNOariEkmr1kjqnG6N/YNaWuMYJ3BUobvLL4g=
RequestId: 480E0B98-ACA5-4C98-AA82-6D9901CD7EE4
- 表单上传
FormPostApplication代码:
public class FormPostApplication {
// The local file path to upload.
private String localFilePath = "d:/trade_stock.sql";
// OSS domain, such as http://oss-cn-hangzhou.aliyuncs.com
private String endpoint = Constants.endpoint;
// Access key Id. Please get it from https://ak-console.aliyun.com
private String accessKeyId = "STS.NTcqigyooFzFUeV2GRZPWDLt8";
private String accessKeySecret = "HwdZYJ8wVUopdNscwDYFf7oPgBpA4WXgG6K4JggztqW9";
private String oss_security_token= "CAISjwJ1q6Ft5B2yfSjIr5fWOtPTlLBO8bitV0Pn1kcHVt97q4nf2jz2IHxMenFgA+sfv/0ynGBR5/YSlrt0UIRyTEfPYNBr2Y9a6higZIyZW2tYUAhC2vOfAmG2J0PR7q27OpfELr70fvOqdCqz9Etayqf7cjOPRkGsNYbz57dsctUQWHvXD1dBH8wEZHEhyqkgOGDWKOymPzPzn2PUFzAIgAdnjn5l4qnNpa/54xHF3lrh0b1X9cajYLrcNpQyY80kDorsgrwrLfSbiBQ9sUYaqP1E64Vf4irCs92nBF1c3g6LKeK88Kc0cFcnPvhgQPcV9aWkxaQp6rzJ8Z7+zlNKJvoQWi/USZu70Fd2+ykG8lpTGoABUJly6VzNT0fNrAW2uTyuuGX+PI/PaV7df5cewy7WoAnvtjDe0PM8vBWuD6zY3dQFgQOPFkY8RxxQUrSkZ9wpS3E7FBjzTfkFGlRHmmc+ad8uCLPaWIb/B9QGI6uKidSXnEnLqcK+8xsB1HBsyCkL600PJfcuSWBs9CHh9uiJTG0=";
// The existing bucket name
private String bucketName = Constants.bucketName;
// The key name for the file to upload.
private String key = "trade_stock";
private void postObject() throws Exception {
// append the 'bucketname.' prior to the domain, such as http://bucket1.oss-cn-hangzhou.aliyuncs.com.
String urlStr = endpoint.replace("http://", "http://" + bucketName + ".");
// form fields
Map<String, String> formFields = new LinkedHashMap<String, String>();
// key
formFields.put("key", this.key);
// Content-Disposition
formFields.put("Content-Disposition", "attachment;filename="
+ localFilePath);
// OSSAccessKeyId
formFields.put("OSSAccessKeyId", accessKeyId);
// policy
String policy
= "{\"expiration\": \"2120-01-01T12:00:00.000Z\",\"conditions\": [[\"content-length-range\", 0, 104857600]]}";
String encodePolicy = new String(Base64.encodeBase64(policy.getBytes()));
formFields.put("policy", encodePolicy);
// Signature
String signaturecom = computeSignature(accessKeySecret, encodePolicy);
formFields.put("Signature", signaturecom);
// Set security token.
formFields.put("x-oss-security-token", oss_security_token);
String ret = formUpload(urlStr, formFields, localFilePath);
System.out.println("Post Object [" + this.key + "] to bucket [" + bucketName + "]");
System.out.println("post reponse:" + ret);
}
private static String computeSignature(String accessKeySecret, String encodePolicy)
throws UnsupportedEncodingException, NoSuchAlgorithmException, InvalidKeyException {
// convert to UTF-8
byte[] key = accessKeySecret.getBytes("UTF-8");
byte[] data = encodePolicy.getBytes("UTF-8");
// hmac-sha1
Mac mac = Mac.getInstance("HmacSHA1");
mac.init(new SecretKeySpec(key, "HmacSHA1"));
byte[] sha = mac.doFinal(data);
// base64
return new String(Base64.encodeBase64(sha));
}
private static String formUpload(String urlStr, Map<String, String> formFields, String localFile)
throws Exception {
String res = "";
HttpURLConnection conn = null;
// String boundary = "9431149156168";
String boundary = "abc";
try {
URL url = new URL(urlStr);
conn = (HttpURLConnection)url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(30000);
conn.setDoOutput(true);
conn.setDoInput(true);
conn.setRequestMethod("POST");
conn.setRequestProperty("User-Agent",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; zh-CN; rv:1.9.2.6)");
// Set Content-MD5. The MD5 value is calculated based on the whole message body.
//conn.setRequestProperty("Content-MD5", "<yourContentMD5>");
conn.setRequestProperty("Content-Type",
"multipart/form-data; boundary=" + boundary);
OutputStream out = new DataOutputStream(conn.getOutputStream());
// text
if (formFields != null) {
StringBuffer strBuf = new StringBuffer();
Iterator<Entry<String, String>> iter = formFields.entrySet().iterator();
int i = 0;
while (iter.hasNext()) {
Entry<String, String> entry = iter.next();
String inputName = entry.getKey();
String inputValue = entry.getValue();
if (inputValue == null) {
continue;
}
if (i == 0) {
strBuf.append("--").append(boundary).append("\r\n");
strBuf.append("Content-Disposition: form-data; name=\""
+ inputName + "\"\r\n\r\n");
strBuf.append(inputValue);
} else {
strBuf.append("\r\n").append("--").append(boundary).append("\r\n");
strBuf.append("Content-Disposition: form-data; name=\""
+ inputName + "\"\r\n\r\n");
strBuf.append(inputValue);
}
i++;
}
out.write(strBuf.toString().getBytes());
}
// file
File file = new File(localFile);
String filename = file.getName();
String contentType = new MimetypesFileTypeMap().getContentType(file);
if (contentType == null || contentType.equals("")) {
contentType = "application/octet-stream";
}
StringBuffer strBuf = new StringBuffer();
strBuf.append("\r\n").append("--").append(boundary)
.append("\r\n");
strBuf.append("Content-Disposition: form-data; name=\"file\"; "
+ "filename=\"" + filename + "\"\r\n");
strBuf.append("Content-Type: " + contentType + "\r\n\r\n");
out.write(strBuf.toString().getBytes());
DataInputStream in = new DataInputStream(new FileInputStream(file));
int bytes = 0;
byte[] bufferOut = new byte[1024];
while ((bytes = in.read(bufferOut)) != -1) {
out.write(bufferOut, 0, bytes);
}
in.close();
byte[] endData = ("\r\n--" + boundary + "--\r\n").getBytes();
out.write(endData);
out.flush();
out.close();
// Gets the file data
strBuf = new StringBuffer();
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = null;
while ((line = reader.readLine()) != null) {
strBuf.append(line).append("\n");
}
res = strBuf.toString();
reader.close();
reader = null;
} catch (Exception e) {
System.err.println("Send post request exception: " + e);
throw e;
} finally {
if (conn != null) {
conn.disconnect();
conn = null;
}
}
return res;
}
public static void main(String[] args) throws Exception {
FormPostApplication ossPostObject = new FormPostApplication();
ossPostObject.postObject();
}
}
-
将上面所获取的key,secret和token填入。
-
bucket名称要和上面授权对应的bucket一致。
-
这里是模拟form表单提交,编码采用UTF-8。
-
policy里面可以配置超时时间, 内容长度范围等。
-
如果出现403错误,检查token等权限信息的配置是否正确。
-
如果出现400错误, 检查参数配置是否正确, 比如说MD5参数如果传递, 但没配置正确, 会出现此错误。
conn.setRequestProperty("Content-MD5", "<yourContentMD5>");
操作成功后, 能够在后台看到对应的文件信息。
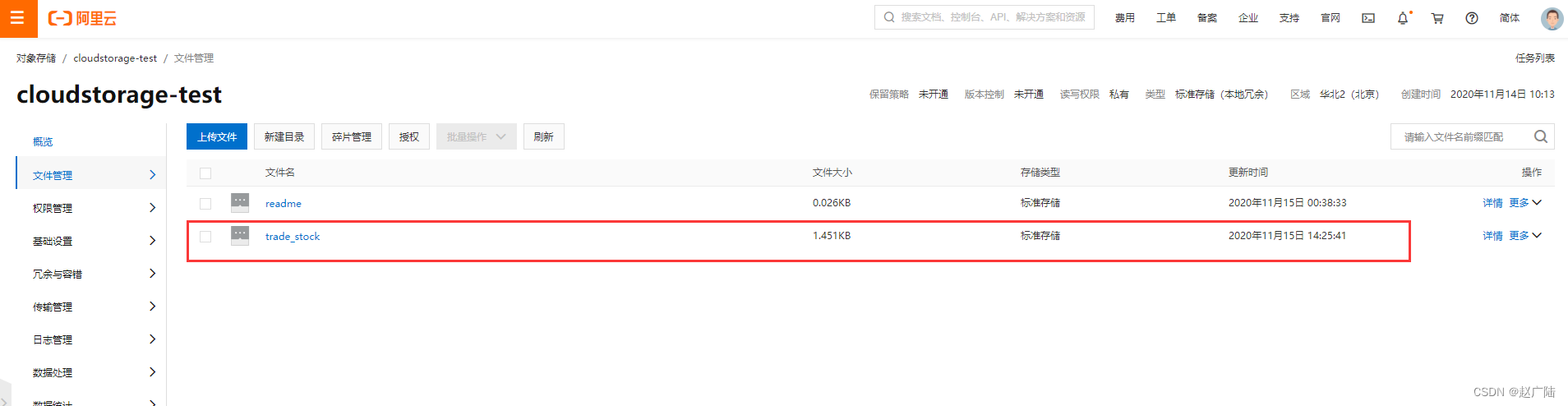
4. 服务上传验证
- 代码:
- 添加阿里云依赖。
- 添加阿里云配置信息。
- 采用表单方式上传, 直接将数据存至OSS服务中。实现类: FormFileUploadServiceImpl。
- 打包app-file服务
maven clean install
- 上传至云服务器
运行:
java -jar app-file.jar
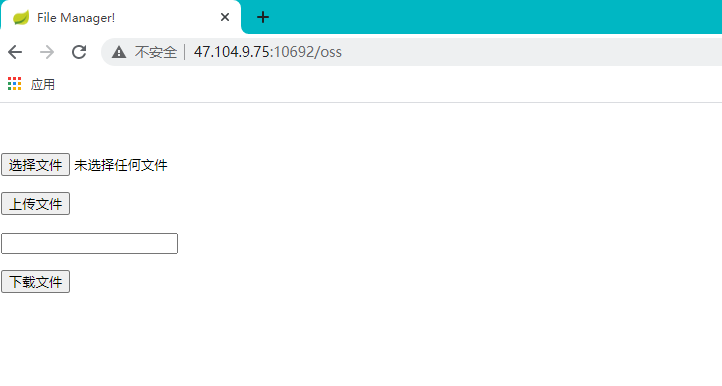
- 功能验证
对文件上传和下载进行验证。
5. 云数据库
- 云数据库 VS 传统数据库
云数据库和传统数据库在搭建、运维、管理层面,云数据库提升了一个层次,实现了较高程度的智能化和自动化,极大地提升了用户友好度,降低了使用门槛。比如灵活的性能等级调整、详尽的监控体系、攻击防护机制等等。
云数据库的高级特性:
-
读写分离
提供可视化的读写分离配置管理功能。从数据库实例的创建, 到同步关系以及读写流量分发, 云数据库都能自动化完成。
 -
自动调优
云数据库都自带性能分析和改进的模块, 能够自动地发现性能热点,还能够智能地给出调整建议,比如进行个别语句的调整,添加额外的索引等等。云数据库的性能分析和自动调优的能力,是将生产运行数据和服务内置的 AI 模型进行了结合,做到了真正的智能化运维, 极大的节省了成本。
阿里云的数据库自治服务DAS:
自治服务DAS是一种基于机器学习和专家经验实现数据库自感知、自修复、自优化、自运维及自安全的云服务,使用了DAS之后您可以避免这样的复杂性和人工操作引起的故障,有效保障数据库服务的稳定、安全及高效。
 -
监控维护
云数据库提供了全面强大的监控维护功能, 提供了丰富的性能监控项,能够及时发现并预警。
监控包含CPU和内存使用率、磁盘空间、IOPS、连接数、CPU内存使用率和网络流量等。
报警功能:
可以根据不同的规则来组合设定预警条件:

6. 云数据库操作
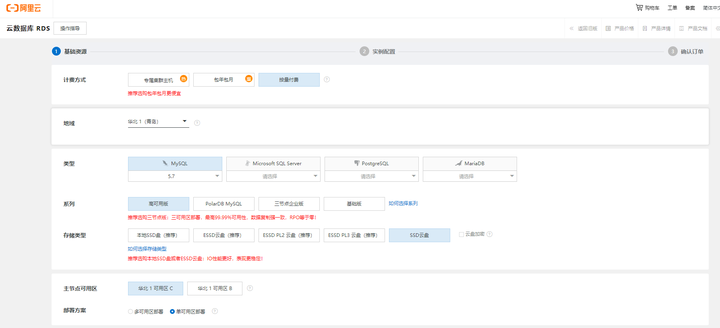
- 创建云数据库实例
根据自身需要, 选择相应配置:
- 访问权限配置
申请外网访问地址:
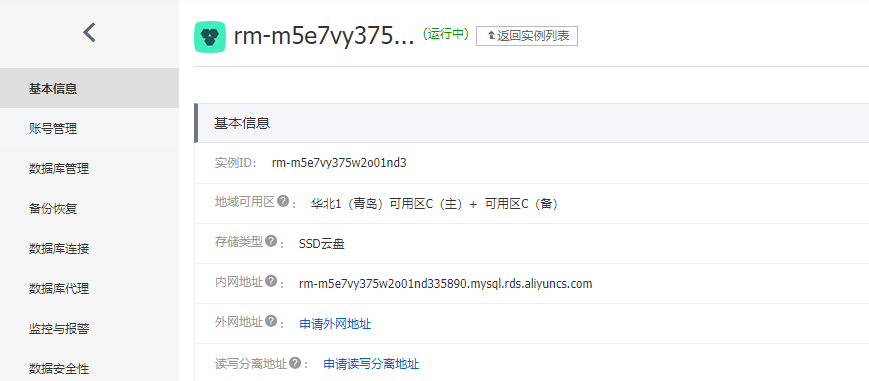
这里提供了内网和外网不同访问地址。
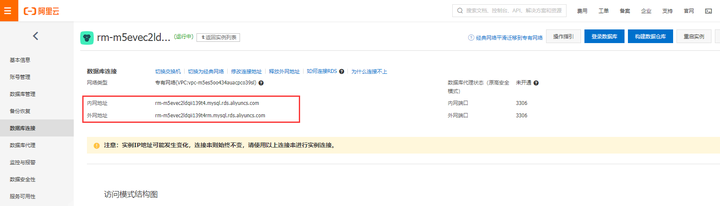
需要设定白名单, 0.0.0.0/0是允许所有主机访问, 在实际应用中, 最好要指定具体的IP。
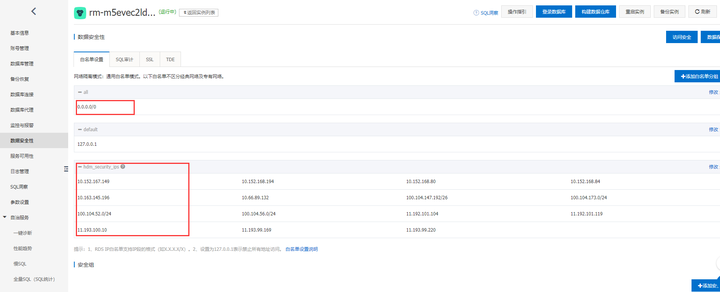
hdm_security_ips是DAS服务白名单, 自动生成。
- 数据库账号配置
创建访问数据库的账号密码。
服务授权标签可以开通配置权限与数据权限。
- 连接配置
- SQL洞察
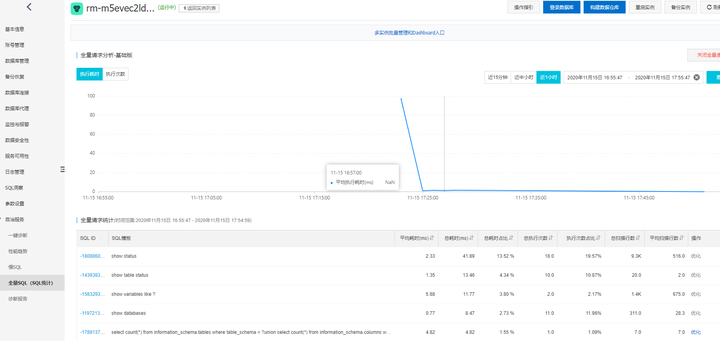
连入数据库后, 做一些SQL操作, 通过SQL洞察就能看到详细的信息:

- 全量SQL统计
这里面会侧重性能分析, 并给出自动优化提示。
7. 服务连接云数据库
- 代码
- 编写下单与查询订单的接口。
- 配置数据源连接, 指向云数据库。
- 采用JPA方式对数据进行操作。
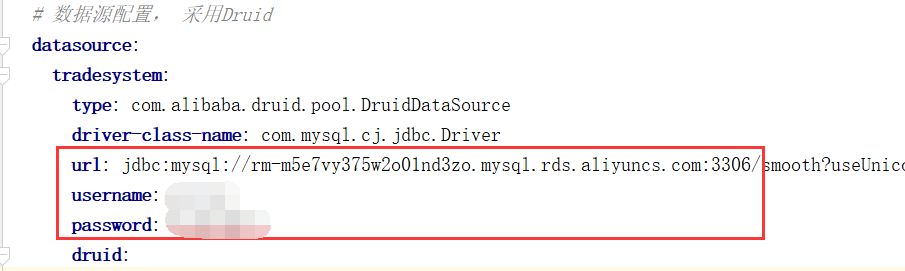
- 修改连接配置
修改application.yml配置文件:
- 服务打包
maven clean install
- 上传至云服务器
运行:
java -jar app-server.jar
- 功能验证
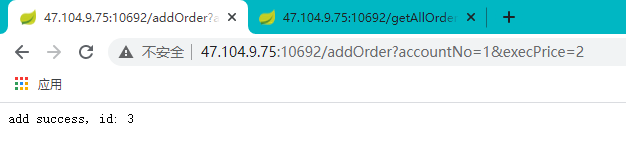
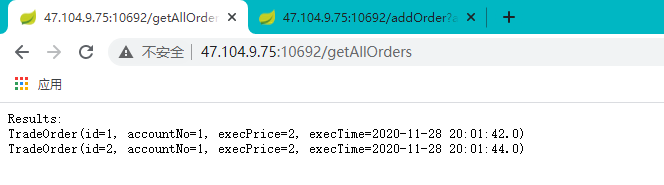
测试数据库的新增与查询功能。
新增: http://47.104.9.75:10692/addOrder?accountNo=1&execPrice=2
查询:http://47.104.9.75:10692/getAllOrders
8. 新一代原生数据库
- 新一代原生数据库 VS 云数据库
-
更强的性能与扩展性
云原生数据库由于原生设计, 专门为云设计的专业化存储架构, 可以支撑更大规模的数据量,关系型云原生数据库能够脱离典型的数 TB 的容量上限,达到单库数十 TB 甚至百 TB 的级别。
云原生数据库可以利用云快速地进行水平扩展,迅速调整、提升数据库的处理能力, 能够有效应对高并发场景。
-
更高的可用性与可靠性
云原生数据库默认就具备多副本高可用的,数据同步、读写分离等高级特性,比如Amazon Aurora云原生数据库, 就自动包含了分布在 3 个可用区、多达 6 份的数据副本。
对于多种数据模型也有很好的支持, 除了兼容关系型数据库外, 还会推出适合不同形态和查询范式的云数据库,与 NoSQL 数据库形成竞争, 比如说AWS的图数据库 Neptune,Azure Cosmos DB的NoSQL 数据库服务。
-
低成本与易维护性
大部分云原生数据库, 在存储上不需要预先设置大小, 会随着存储占用自动扩展;在计算上, 也有部分云数据库推出了无服务器版本,比如 亚马逊 的 Aurora Serverless,在面对间歇偶发性工作负载时,都能节省较多的成本。
- 阿里云PolarDB

阿里云 PolarDB 放弃了通用分布式数据库OLTP多路并发写的支持,采用一写多读的架构设计,存储与计算分离的技术架构,简化了分布式系统难以兼顾的理论模型,又能满足绝大多数OLTP的应用场景和性能要求。
PolarDB 的设计革新:
-
通过重新设计特定的文件系统来存取 Redo log 这种特定的 WAL I/O 数据。
-
通过高速网络和高效协议将数据库文件和 Redo log 文件放在共享存储设备上,避免了多次长路径 I/O 的重复操作,并且针对 Redolog的I/O 路径,专门设计了多副本共享存储块设备。
-
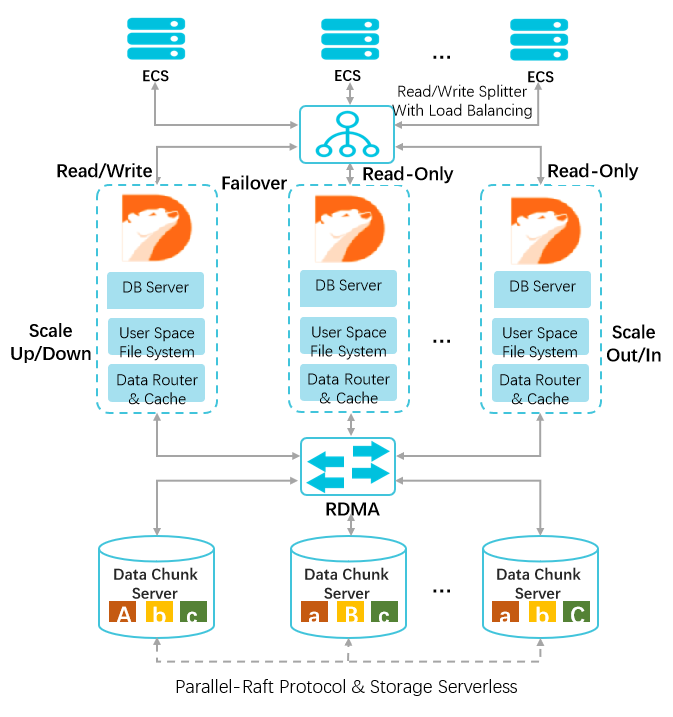
产品架构设计
-
一写多读
主节点处理读写请求,只读节点仅处理读请求。一个集群版集群包含一个主节点和最多15个只读节点。
-
计算与存储分离
计算与存储分离的设计,计算节点仅存储元数据, 存储节点负责数据文件、Redo Log等存储。
-
共享分布式存储
多个计算节点共享一份数据,并非每个计算节点都存储一份数据, 降低存储成本。存储节点的数据采用多副本形式,确保数据的可靠性,并通过Parallel-Raft协议保证数据一致性。基于全新设计的分布式块存储和文件系统,存储容量可以在线平滑扩展。
- POLARDB 2.0 vs POLARDB 1.0
PolarDB-X 1.0 是基于DRDS + RDS 的分布式云数据库服务, 产品的特征是采用 Share-Nothing 架构、以解决存储扩展性为出发点、提供面向用户的产品化交付能力。
PolarDB-X 2.0 主要是解决企业的各种复杂需求:
- 在功能性方面, 既要保障SQL通用性, 又要具备NoSQL的扩展性;既要高并发, 又要支持实时复杂分析。
- 企业的历史沉淀数据是一大痛点, 要以最少的成本保障数据能够顺利稳定的迁移, 并且不影响现有服务的稳定性。
- 各种应用对GIS数据的处理需求会越来越旺盛,使用开源版本GIS性能、功能无法满足,需要有一个功能强大的存储介质。
- 海量数据的运维管理, 高级DBA非常欠缺,在维护方面需要高昂的成本。
针对以上问题, POLARDB2.0应运而生,不但完全继承了1.0的架构体系,同时兼容了另外两个流行数据库Oracle与PostgreSQL。POLARDBv2.0forOracle,高度兼容Oracle;POLARDBv2.0 for PostgreSQL,完全兼容PostgreSQL。
9 阿里云PolarDB生产最佳实践
- 创建PolarDB-X 2.0实例
创建实例一定要选择专有的网络和交换机, 注意可用区要匹配正确。
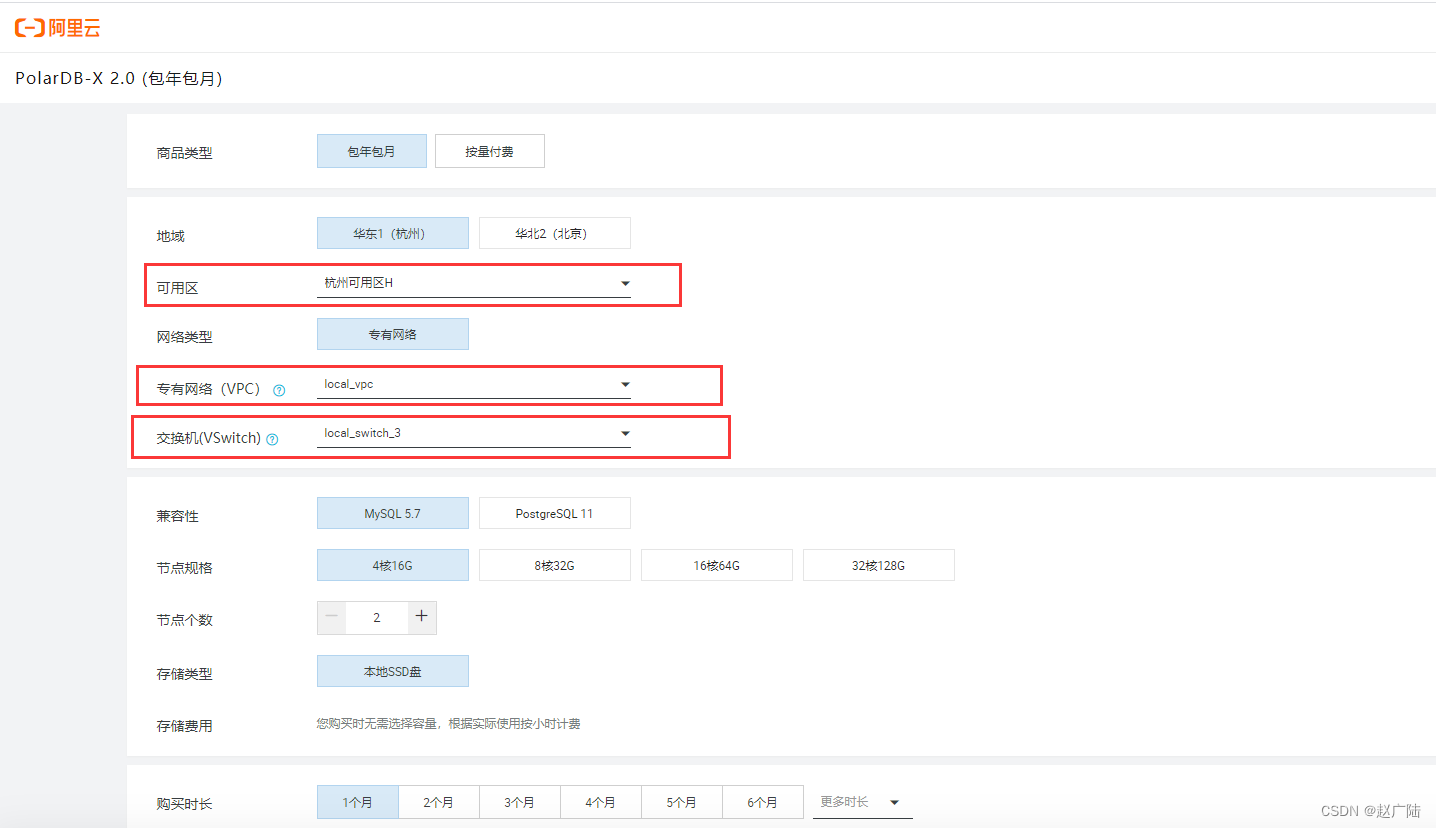
创建好专有网络和交换机
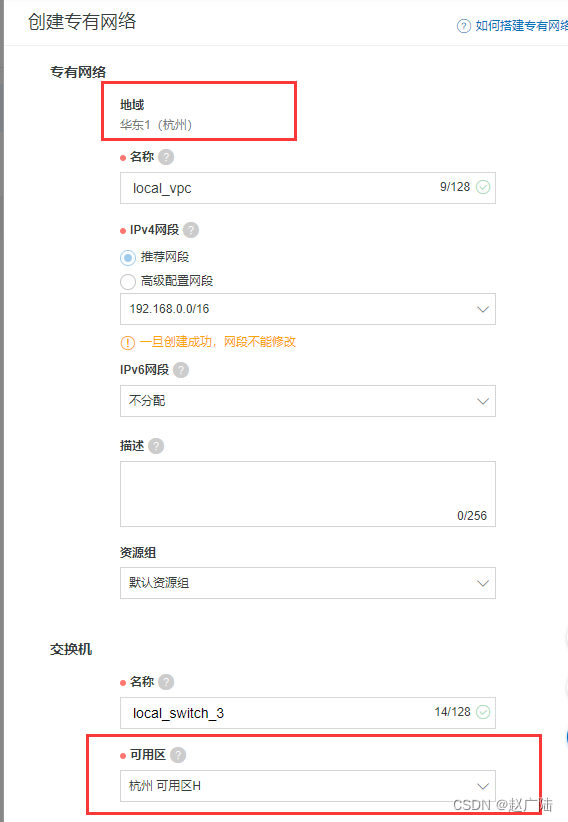
- 配置外网
- 设置白名单

这里为便于测试,允许所有外网地址连入, 实际使用当中, 应设置为指定的IP。
- 申请外网连接地址
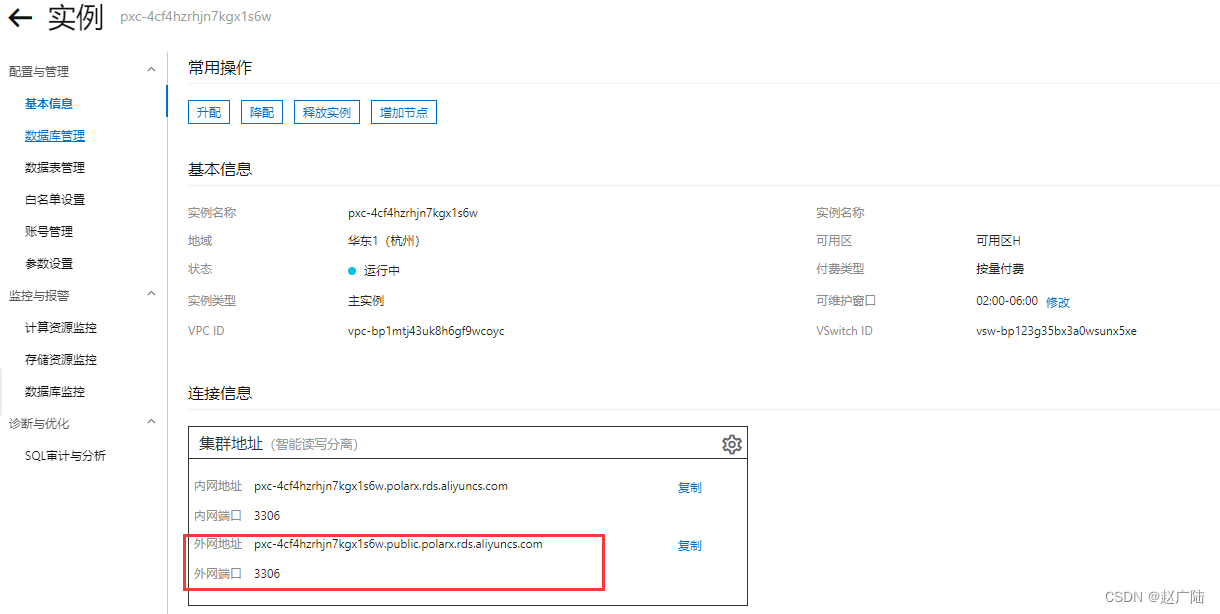
如果是内部虚拟机, 通过vpc内部网络接入, 要选择内网地址。
- 客户端连接
外网接入测试:
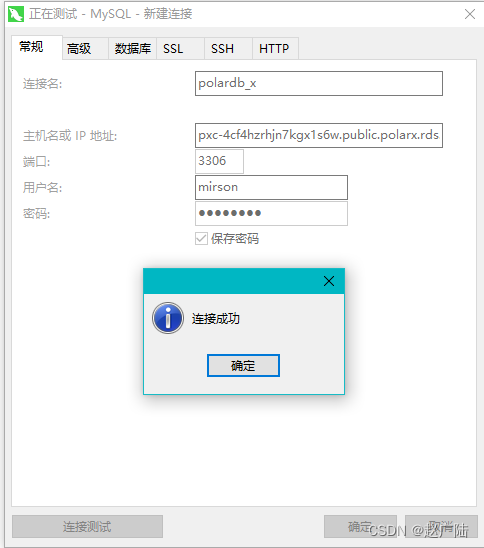
(如果不能连接出现超时, 可以尝试再添加只读实例, 还是不行的话, 可以提请工单请后台人员处理)
如果应用服务连接, 直接修改application.yml中的数据库连接配置即可。
- 分区的使用
根据用户标识与时间字段相结合作为拆分键,并按照一周七天进行分表:
CREATE TABLE user_log (
userId INT(11) NOT NULL,
name VARCHAR(64) NOT NULL,
operation VARCHAR(128) DEFAULT NULL,
actionDate DATE DEFAULT NULL
) DBPARTITION BY HASH(userId) TBPARTITION BY WEEK(actionDate) TBPARTITIONS 7
PolarDB-X将拆分键值通过拆分函数计算得到一个计算结果,然后根据这个结果将数据分拆到私有定制RDS实例上。
创建完成之后, 可以看到对应的信息:

- 如何配置分片数
在实际应用中, 经常会面临分库分表的场景, PolarDB-X建议单个物理分表的容量不超过500万行数据。通常可以预估1~2年内的数据增长量,用估算出的总数据量除以总的物理分库数,再除以建议的单个物理分表的最大数据量(即500万),即可得出每个物理分库上需要创建的物理分表数。
计算公式:
物理分库上的物理分表数=向上取整(估算的总数据量/(私有定制RDS实例数 x 8)/ 5,000,000)
示例:
假设预估一张表在2年后的总数据量约为1亿行,如果已购买了2个私有定制RDS实例,那么按照分片数公式进行如下计算:
物理分库上的物理分表数= CEILING(100,000,000 / ( 2 * 8 ) / 5,000,000) = CEILING(1.25) = 2
结果为2,那么需要在每个物理分库上再创建2张物理分表。
- 连接池配置
在实际生产当中, 官方推荐使用Druid连接池(最低要求版本1.1.11)
Druid与Spring的集成配置示例:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<!-- 基本属性 URL、user、password -->
<property name="url" value="jdbc:mysql://ip:port/db?autoReconnect=true&rewriteBatchedStatements=true&socketTimeout=30000&connectTimeout=3000" />
<property name="username" value="root" />
<property name="password" value="123456" />
<!-- 配置初始化大小、最小、最大 -->
<property name="maxActive" value="20" />
<property name="initialSize" value="3" />
<property name="minIdle" value="3" />
<!-- maxWait 获取连接等待超时的时间 -->
<property name="maxWait" value="60000" />
<!-- timeBetweenEvictionRunsMillis 间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- minEvictableIdleTimeMillis 一个连接在池中最小空闲的时间,单位是毫秒-->
<property name="minEvictableIdleTimeMillis" value="300000" />
<!-- 检测连接是否可用的 SQL -->
<property name="validationQuery" value="select 'z' from dual" />
<!-- 是否开启空闲连接检查 -->
<property name="testWhileIdle" value="true" />
<!-- 是否在获取连接前检查连接状态 -->
<property name="testOnBorrow" value="false" />
<!-- 是否在归还连接时检查连接状态 -->
<property name="testOnReturn" value="false" />
<!-- 是否在固定时间关闭连接。此参数默认可以不加,但是增加此参数可以均衡后端服务节点参数 -->
<property name="phyTimeoutMillis" value="1800000" />
<!-- 是否在固定SQL使用次数之后关闭连接,此参数默认可以不加,但是增加此参数可以均衡后端服务节点参数-->
<property name="phyMaxUseCount" value="10000" />
</bean>
- 如何平滑扩容
首先判断是否需要扩容:
- CPU 及 IOPS 指标
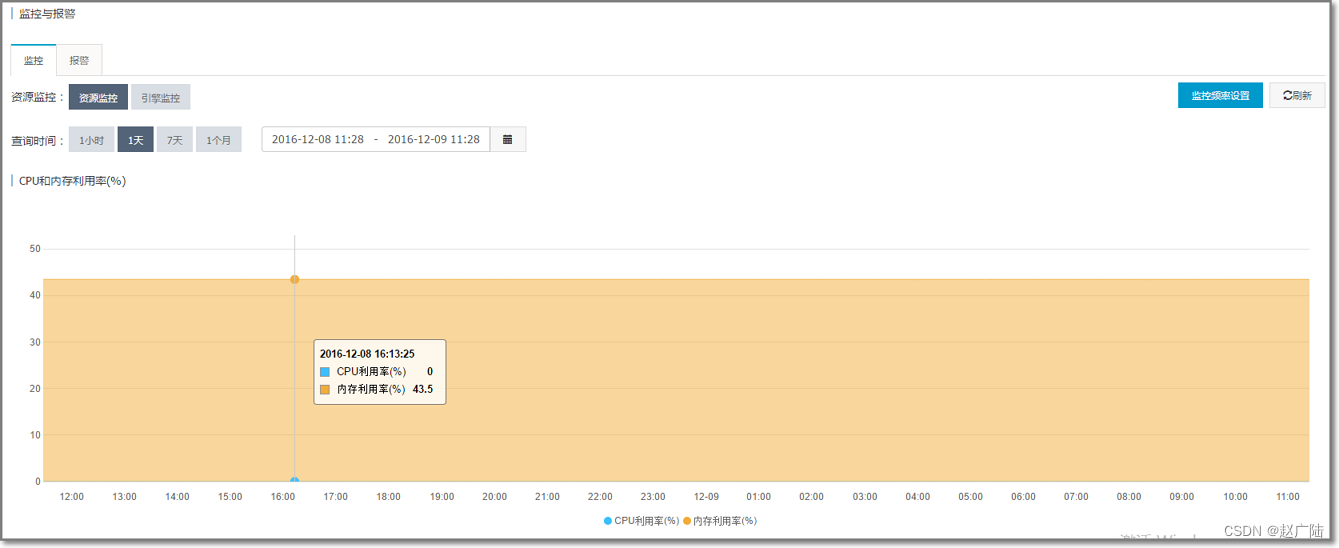
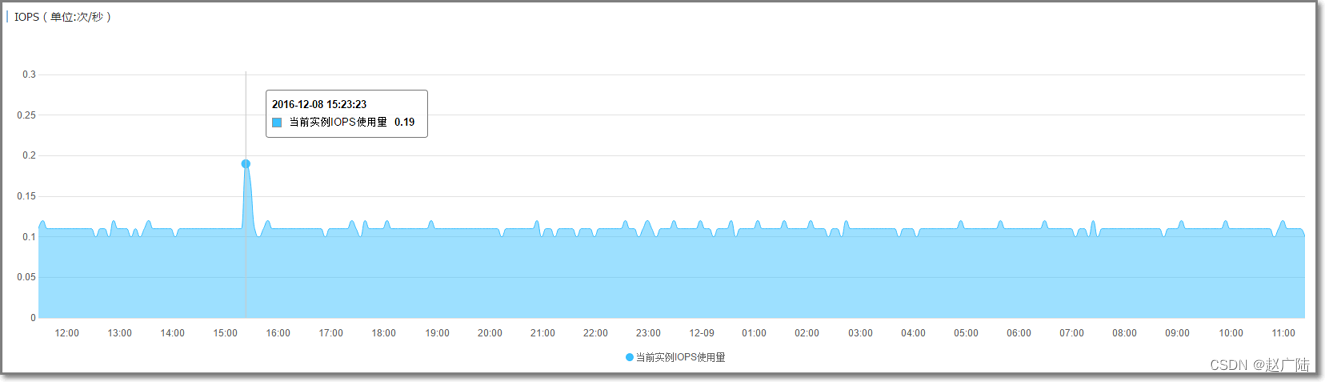
如果发现任何一个指标长期保持在80%以上, 并且通过优化手段也无法解决, 那么可以考虑扩容。
- 磁盘空间
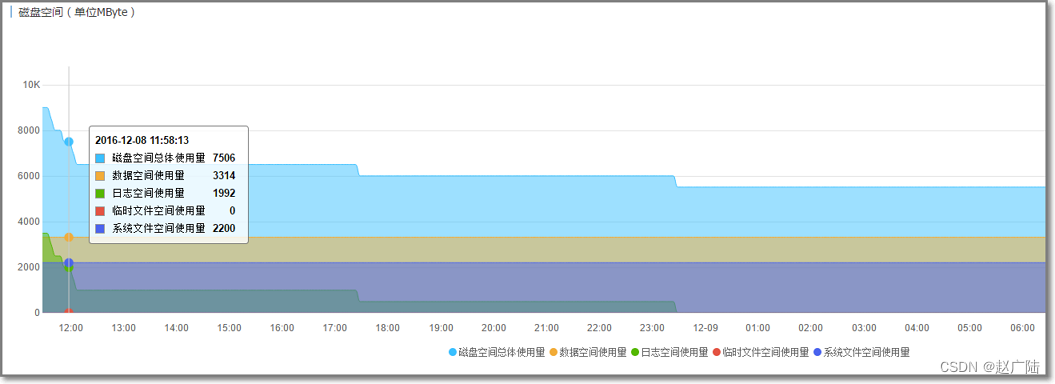
当数据空间将要或预期要超出磁盘容量时,可以通过扩容的方式将数据分散到多个 RDS。
- 扩容前注意事项
- 如果需要新增5个或5个以上 RDS 实例,需要事先提工单,以防平台后端迁移资源不足造成迁移不成功。
- 源 RDS 实例扩容过程中会有读压力,尽量在低负载时操作。
- 扩容期间请勿在控制台提交 DDL 任务或连接 PolarDB-X 直接执行 DDL SQL,否则会导致扩容任务失败。
- 扩容需要源库表中有主键,如果没有需要事先加好主键。
- 扩容的切换动作会将读写流量切换到新增的 RDS 上,切换过程大约持续3~5分钟,建议在停业务的情况下进行切换。
- 在执行切换前,扩容动作不会对 PolarDB-X 产生任何影响。因此在切换前都可以通过回滚来放弃本次扩容。
- 扩容操作步骤
扩容主要分为配置>迁移>切换>清理 四个步骤。
详情可以查阅 官方文档