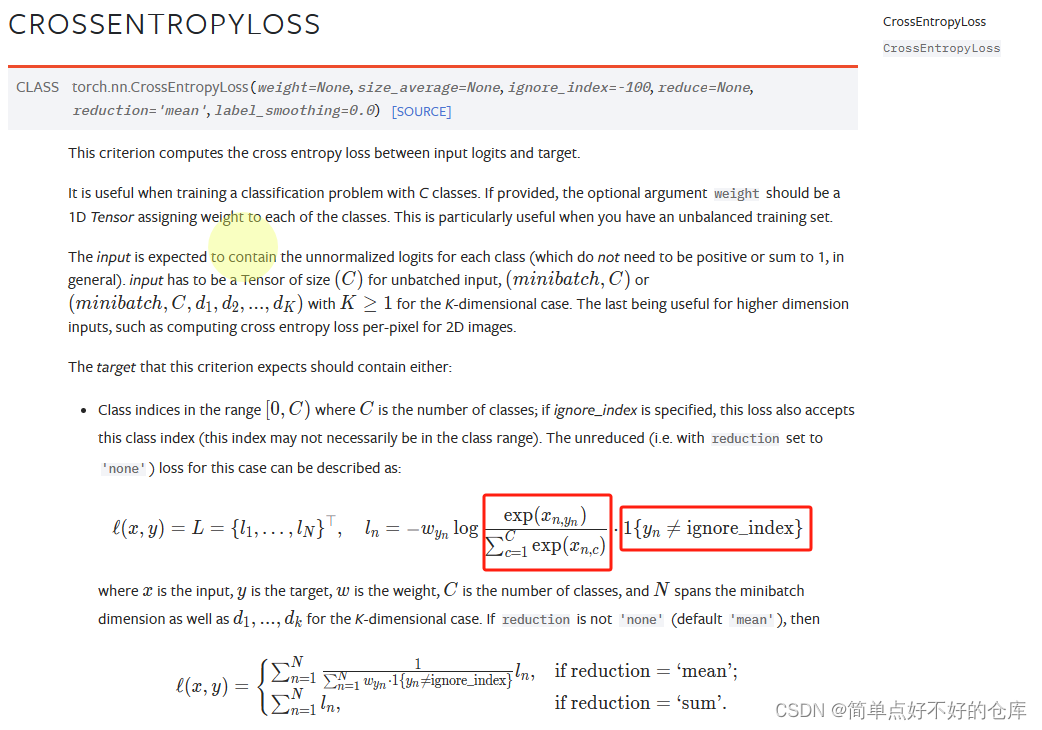
准备:
master01(2C/4G,cpu核心数要求大于2) 192.168.80.20
master02(2C/4G,cpu核心数要求大于2) 192.168.80.14
master03(2C/4G,cpu核心数要求大于2) 192.168.80.15
环境准备:
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
iptables -F
swapoff -a #交换分区必须要关闭
#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
//修改主机名
hostnamectl set-hostname master01
hostnamectl set-hostname master02
hostnamectl set-hostname master03
//所有节点修改hosts文件
vim /etc/hosts
192.168.80.20 master01
192.168.80.14 master02
192.168.80.15 master03
//调整内核参数
cat > /etc/sysctl.d/kubernetes.conf << EOF
#开启网桥模式,可将网桥的流量传递给iptables链
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1
#关闭ipv6协议
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
EOF
//生效参数
sysctl --system 1,所有节点安装docker
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce docker-ce-cli containerd.io
mkdir /etc/docker
cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": ["https://6ijb8ubo.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
}
}
EOF
#使用Systemd管理的Cgroup来进行资源控制与管理,因为相对Cgroupfs而言,Systemd限制CPU、内存等资源更加简单和成熟。
#日志使用json-file格式类型存储,大小为100M,保存在/var/log/containers目录下,方便ELK等日志系统收集和管理日志。
systemctl daemon-reload
systemctl restart docker.service
systemctl enable docker.service
-------------------- 所有节点安装kubeadm,kubelet和kubectl --------------------
//定义kubernetes源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum install -y kubelet-1.15.1 kubeadm-1.15.1 kubectl-1.15.1
//开机自启kubelet
systemctl enable kubelet.service
#K8S通过kubeadm安装出来以后都是以Pod方式存在,即底层是以容器方式运行,所以kubelet必须设置开机自启
2,部署master节点
//在 master01 节点操作
//上传 kubeadm-basic.images.tar.gz、start.keep.tar.gz、haproxy.tar、keepalived.tar、flannel.tar 压缩包文件至 /opt 目录
cd /opt
tar zxvf kubeadm-basic.images.tar.gz
tar zxvf start.keep.tar.gz -C /
//编写自动导入镜像的脚本
vim load-images.sh
#!/bin/bash
mv /opt/*.tar /opt/kubeadm-basic.images/
cd /opt/kubeadm-basic.images
for i in $(ls /opt/kubeadm-basic.images)
do
docker load -i $i
done
bash load-images.sh
//配置并启动 haproxy 和 keepalived
cd /data/lb/
vim etc/haproxy.cfg
...... #在末尾设置集群节点,这里为了防止haproxy负载转发到空节点上,先开启一个当前节点
49 server rancher01 192.168.80.20:6443
50 #server rancher02 192.168.80.14:6443
51 #server rancher03 192.168.80.15:6443
vim start-haproxy.sh
#!/bin/bash
MasterIP1=192.168.80.20 #指定 master01 的IP地址
MasterIP2=192.168.80.14 #指定 master02 的IP地址
MasterIP3=192.168.80.15 #指定 master03 的IP地址
MasterPort=6443
docker run -d --restart=always --name HAProxy-K8S -p 6444:6444 \
-e MasterIP1=$MasterIP1 \
-e MasterIP2=$MasterIP2 \
-e MasterIP3=$MasterIP3 \
-e MasterPort=$MasterPort \
-v /data/lb/etc/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg \
wise2c/haproxy-k8s
vim start-keepalived.sh
#!/bin/bash
VIRTUAL_IP=192.168.80.100 #设置集群 VIP 地址
INTERFACE=ens33 #指定网卡名称
NETMASK_BIT=24
CHECK_PORT=6444
RID=10
VRID=160
MCAST_GROUP=224.0.0.18
docker run -itd --restart=always --name=Keepalived-K8S \
--net=host --cap-add=NET_ADMIN \
-e VIRTUAL_IP=$VIRTUAL_IP \
-e INTERFACE=$INTERFACE \
-e CHECK_PORT=$CHECK_PORT \
-e RID=$RID \
-e VRID=$VRID \
-e NETMASK_BIT=$NETMASK_BIT \
-e MCAST_GROUP=$MCAST_GROUP \
wise2c/keepalived-k8s
bash start-haproxy.sh
netstat -natp | grep 6444
tcp 0 0 0.0.0.0:6444 0.0.0.0:* LISTEN 3987/docker-proxy
bash start-keepalived.sh
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:01:00:b4 brd ff:ff:ff:ff:ff:ff
inet 192.168.80.20/24 brd 192.168.80.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.80.100/24 scope global secondary ens33
valid_lft forever preferred_lft forever
//复制镜像和脚本到其它 master 节点
cd /opt
scp -r kubeadm-basic.images load-images.sh root@master02:/opt
scp -r kubeadm-basic.images load-images.sh root@master03:/opt
scp -r /data root@master02:/
scp -r /data root@master03:/
//在其它 master 节点上执行脚本
bash /opt/load-images.sh
bash /data/lb/start-haproxy.sh
bash /data/lb/start-keepalived.sh
//初始化 master01 节点
kubeadm config print init-defaults > /opt/kubeadm-config.yaml
cd /opt/
vim kubeadm-config.yaml
......
11 localAPIEndpoint:
12 advertiseAddress: 192.168.80.20 #指定当前master节点的IP地址
13 bindPort: 6443
......
25 clusterName: kubernetes
26 controlPlaneEndpoint: "192.168.80.100:6444" #指定集群 VIP 地址
27 controllerManager: {}
......
35 kubernetesVersion: v1.15.1 #指定kubernetes版本号
36 networking:
37 dnsDomain: cluster.local
38 podSubnet: "10.244.0.0/16" #指定pod网段,10.244.0.0/16用于匹配flannel默认网段
39 serviceSubnet: 10.96.0.0/16 #指定service网段
40 scheduler: {}
--- #末尾再添加以下内容
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs #把默认的service调度方式改为ipvs模式
kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs | tee kubeadm-init.log
#--experimental-upload-certs 参数可以在后续执行加入节点时自动分发证书文件,k8sV1.16版本开始替换为 --upload-certs
#tee kubeadm-init.log 用以输出日志
提示:
......
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
#此命令是用于在其它 master 节点上执行加入群集
kubeadm join 192.168.80.100:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:b7c84262895d9926c2011d02d234bfb882f97e4774431a0fa20cfc7fa92cec52 \
--control-plane --certificate-key 3ae9868e44b9b2cebcf36a22d7e29b897e6c22bdfe381e8caf9ee2d565575ab1
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
#此命令是用于在其它 node 节点上执行加入群集
kubeadm join 192.168.80.100:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:b7c84262895d9926c2011d02d234bfb882f97e4774431a0fa20cfc7fa92cec52
//按照提示进行配置
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
//在其它 master 节点上执行 kubeadm join 命令加入群集,并按照提示进行配置
kubeadm join 192.168.80.100:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:b7c84262895d9926c2011d02d234bfb882f97e4774431a0fa20cfc7fa92cec52 \
--control-plane --certificate-key 3ae9868e44b9b2cebcf36a22d7e29b897e6c22bdfe381e8caf9ee2d565575ab1
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
//在所有 master 节点上修改 haproxy 配置,开启所有节点,并进行重启
vim /data/lb/etc/haproxy.cfg
......
49 server rancher01 192.168.80.20:6443
50 server rancher02 192.168.80.14:6443
51 server rancher03 192.168.80.15:6443
docker ps -a
4521fa71d127 wise2c/haproxy-k8s "/docker-entrypoint.…" 22 minutes ago Up 22 minutes 0.0.0.0:6444->6444/tcp HAProxy-K8S
docker rm -f HAProxy-K8S && bash /data/lb/start-haproxy.sh
//在 master01 节点上传 kube-flannel.yml 文件到 /opt 目录,并创建 flannel 资源
cd /opt
kubectl apply -f kube-flannel.yml
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5c98db65d4-mknsx 1/1 Running 0 30m
coredns-5c98db65d4-w8tsr 1/1 Running 0 30m
etcd-master01 1/1 Running 0 29m
etcd-master02 1/1 Running 0 23m
etcd-master03 1/1 Running 0 18m
kube-apiserver-master01 1/1 Running 0 29m
kube-apiserver-master02 1/1 Running 0 23m
kube-apiserver-master03 1/1 Running 0 18m
kube-controller-manager-master01 1/1 Running 1 29m
kube-controller-manager-master02 1/1 Running 0 23m
kube-controller-manager-master03 1/1 Running 0 18m
kube-flannel-ds-amd64-f74hm 1/1 Running 0 54s
kube-flannel-ds-amd64-krv4x 1/1 Running 0 54s
kube-flannel-ds-amd64-x2x8v 1/1 Running 0 54s
kube-proxy-7qhtm 1/1 Running 0 23m
kube-proxy-d589b 1/1 Running 0 30m
kube-proxy-xdzk5 1/1 Running 0 18m
kube-scheduler-master01 1/1 Running 1 29m
kube-scheduler-master02 1/1 Running 0 23m
kube-scheduler-master03 1/1 Running 0 18m
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready master 31m v1.15.1
master02 Ready master 23m v1.15.1
master03 Ready master 18m v1.15.1
3,所有 master 节点上修改 K8S 集群配置文件
vim ~/.kube/config
......
#把连接地址修改成各自的节点IP:6443,以防某个master节点故障后,kubectl命令执行被阻塞
5 server: https://192.168.80.20:6443
......
//etcd 集群状态查看
kubectl -n kube-system exec etcd-master01 -- etcdctl \
--endpoints=https://192.168.80.20:2379 \
--ca-file=/etc/kubernetes/pki/etcd/ca.crt \
--cert-file=/etc/kubernetes/pki/etcd/server.crt \
--key-file=/etc/kubernetes/pki/etcd/server.key cluster-health
member 8d213672f975eae is healthy: got healthy result from https://192.168.80.14:2379
member 72de4f571ed38892 is healthy: got healthy result from https://192.168.80.15:2379
member 78af6498bc1a0b41 is healthy: got healthy result from https://192.168.80.20:2379
cluster is healthy
kubectl get endpoints kube-controller-manager --namespace=kube-system -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master01_465eb264-5617-4599-9d99-4e0ec77c419a","leaseDurationSeconds":15,"acquireTime":"2021-06-09T11:46:06Z","renewTime":"2021-06-09T12:19:22Z","leaderTransitions":1}'
creationTimestamp: "2021-06-09T11:37:46Z"
name: kube-controller-manager
namespace: kube-system
resourceVersion: "4455"
selfLink: /api/v1/namespaces/kube-system/endpoints/kube-controller-manager
uid: 28a7a017-3f29-4754-8e7d-c4a73e10c8e4
kubectl get endpoints kube-scheduler --namespace=kube-system -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master01_a947a608-3209-43c1-80f6-bfa28f0ff5d8","leaseDurationSeconds":15,"acquireTime":"2021-06-09T11:46:05Z","renewTime":"2021-06-09T12:19:32Z","leaderTransitions":1}'
creationTimestamp: "2021-06-09T11:37:44Z"
name: kube-scheduler
namespace: kube-system
resourceVersion: "4468"
selfLink: /api/v1/namespaces/kube-system/endpoints/kube-scheduler
uid: 68450192-2999-4a97-ac41-2d9058edc7f9